
Supervised Face Recognition
Project in AI & Deep Learning at ESIEE Paris, co-authored with Lubin Benoit.
Supervisor: Prof. Laurent Najman.
We built an end-to-end face recognition pipeline from raw images to identities, and then measured the impact of each stage.
GitHub code Project report (PDF, fr)
Problem & data
Two datasets:
- Jurassic Park characters (≈218 images) used to design and ablate the pipeline.
- A personal dataset (10 people, 50–110 photos each) to check generalization and bias.
Pipeline (what we compared)
- Detection: dlib HOG vs CNN detector; faces cropped and resized to 128×128.
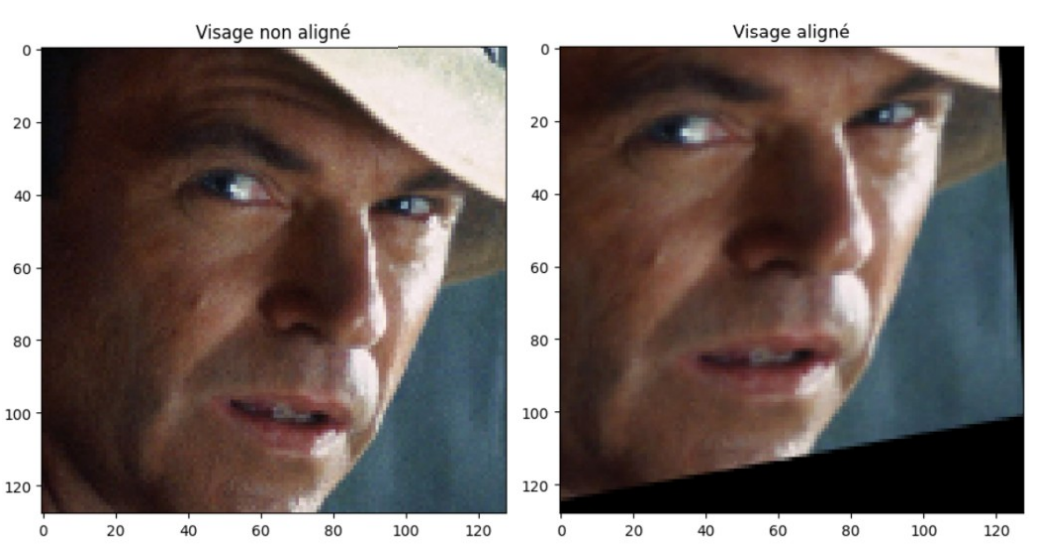
- Pose/Alignment: facial landmarks (5/68 pts) + affine align; reduces pose variance.
- Encoding: 128-D embeddings (OpenFace-style) for compact, robust features.
- Classification: Logistic Regression, Linear SVM, kNN, and a small NN.
Headline result: with embeddings, several classifiers reach ~97% accuracy on test.
Logistic Regression and Linear SVM are the fastest at inference (milliseconds).

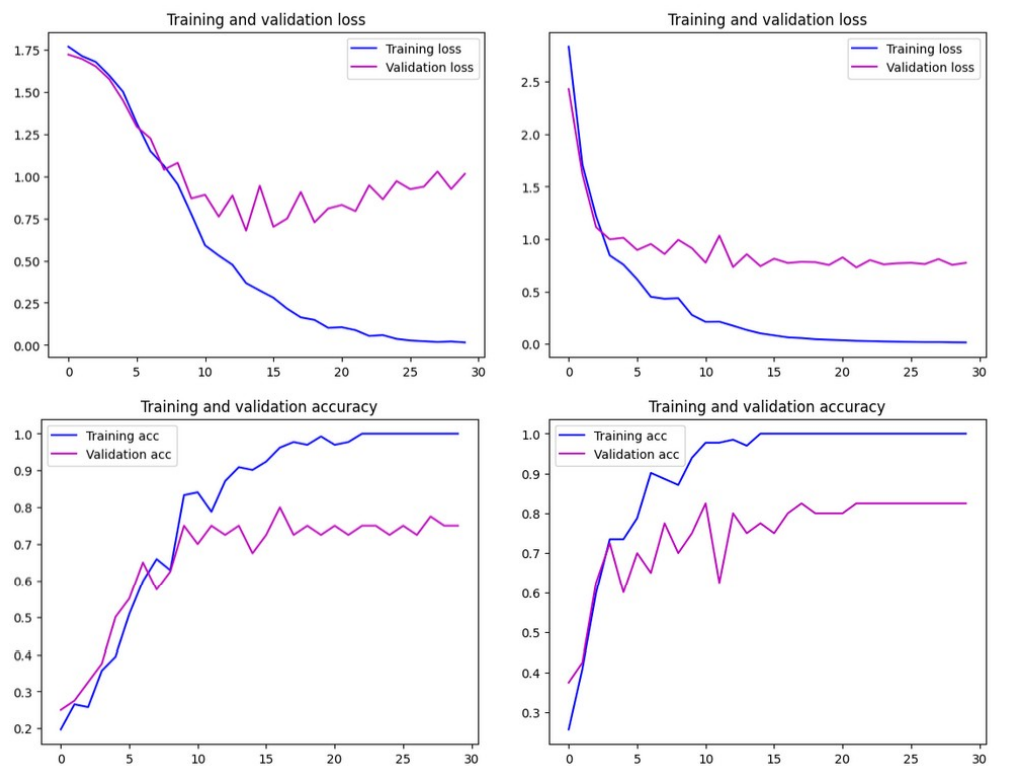
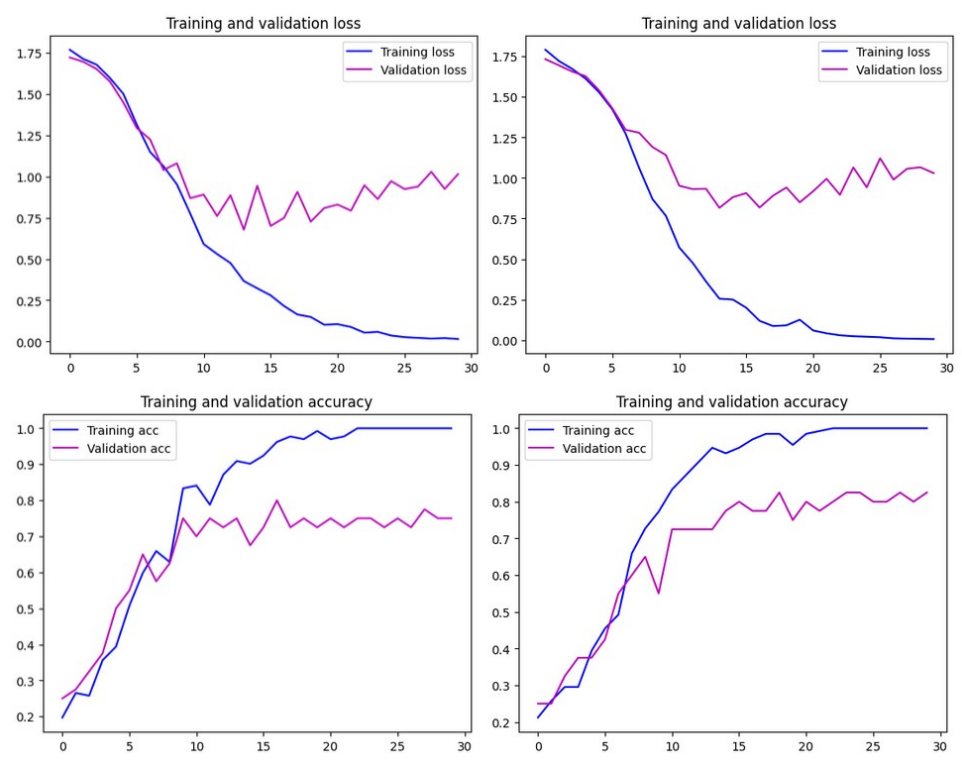
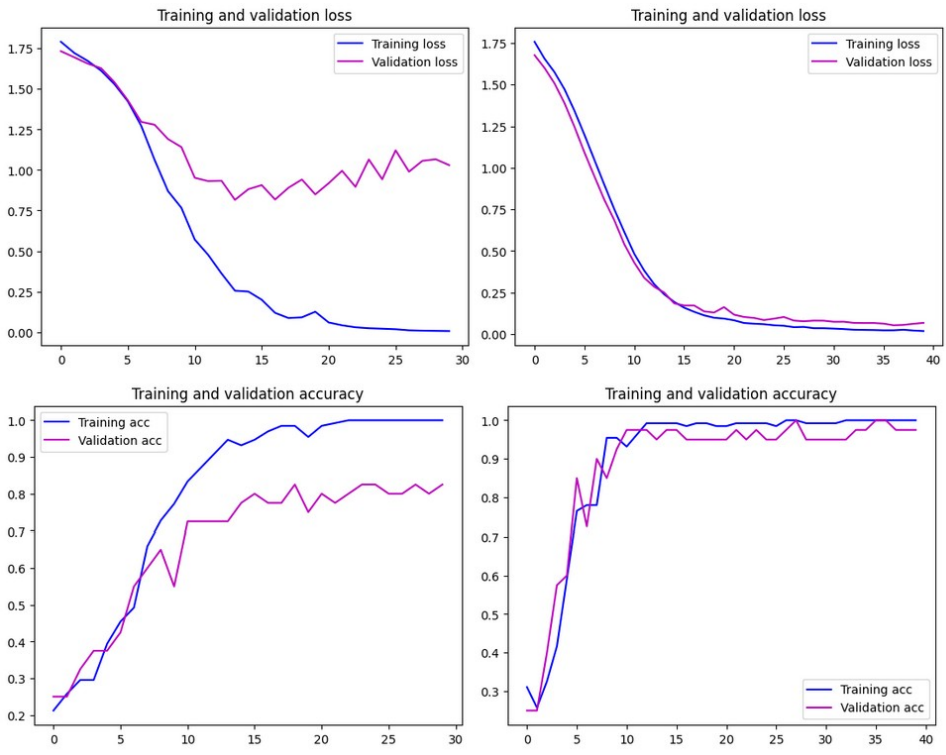

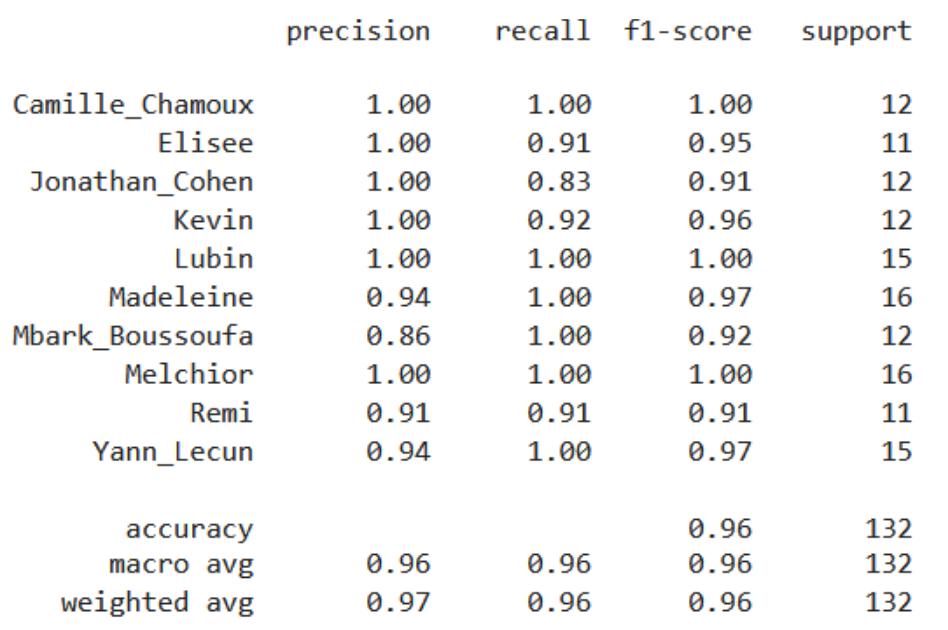
Notes & takeaways
- Alignment helps shallow convnets; deeper models were already robust on this scale.
- Embeddings remove background and lighting noise and let simple classifiers shine.
- Speed matters: for deployment, LogReg/SVM give near-NN accuracy with far lower latency.
- Bias check: with a more varied personal set, accuracy stays high (≈94–98%), but performance depends on data quality and diversity; this is worth monitoring if scaled.